
K Means Clustering Algorithm Tutorial And Example Images
What is K-means Clustering? Unsupervised Machine Learning is the process of teaching a computer to use unlabeled, unclassified data and enabling the algorithm to operate on that data without supervision. Without any previous data training, the machine's job in this case is to organize unsorted data according to parallels, patterns, and variations.

Belajar Data Mining Algoritma KMeans Clustering YouTube
Partitioning Method (K-Mean) in Data Mining. Partitioning Method: This clustering method classifies the information into multiple groups based on the characteristics and similarity of the data. Its the data analysts to specify the number of clusters that has to be generated for the clustering methods. In the partitioning method when database (D.

What Is Kmeans Clustering? 365 Data Science
Data mining methods and techniques, in conjunction with machine learning algorithms, enable us to analyze large data sets in an intelligible manner. k-means is a technique for data clustering that may be used for unsupervised machine learning.

Data Mining KMeans Clustering YouTube
Despite these limitations, the K-means clustering algorithm is credited with flexibility, efficiency, and ease of implementation. It is also among the top ten clustering algorithms in data mining [59], [217], [105], [94].The simplicity and low computational complexity have given the K-means clustering algorithm a wide acceptance in many domains for solving clustering problems.

Data mining [sumber elektronis] penerapan algoritma kmeans
Clustering is a data mining exercise where we take a bunch of data and find groups of points that are similar to each other. K-means is an algorithm that is great for finding clusters in many types of datasets. For more about cluster and k-means, see the scikit-learn documentation on its k-means algorithm or watch this video:
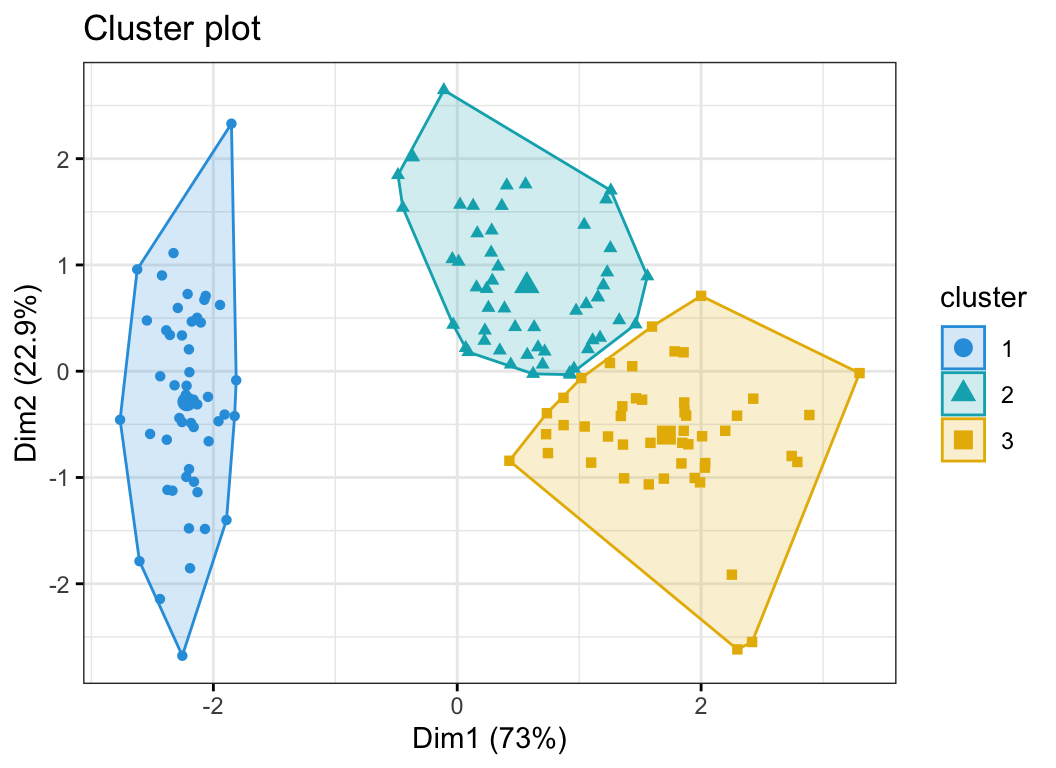
KMeans Clustering Visualization in R Step By Step Guide Datanovia
The k- means clustering algorithm is a data mining and machine learning tool used to cluster observations into groups of related observations without any prior knowledge of those relationships. By sampling, the algorithm attempts to show in which category, or cluster, the data belongs to, with the number of clusters being defined by the value k.

Kmeans clustering 1 Algorithm YouTube
Cluster analysis is a technique used in data mining and machine learning to group similar objects into clusters. K-means clustering is a widely used method for cluster analysis where the aim is to partition a set of objects into K clusters in such a way that the sum of the squared distances between the objects and their assigned cluster mean is.

D rendering of five clusters obtained after applying the Kernel kmeans
The k-means clustering method is an unsupervised machine learning technique used to identify clusters of data objects in a dataset. There are many different types of clustering methods, but k-means is one of the oldest and most approachable.These traits make implementing k-means clustering in Python reasonably straightforward, even for novice programmers and data scientists.
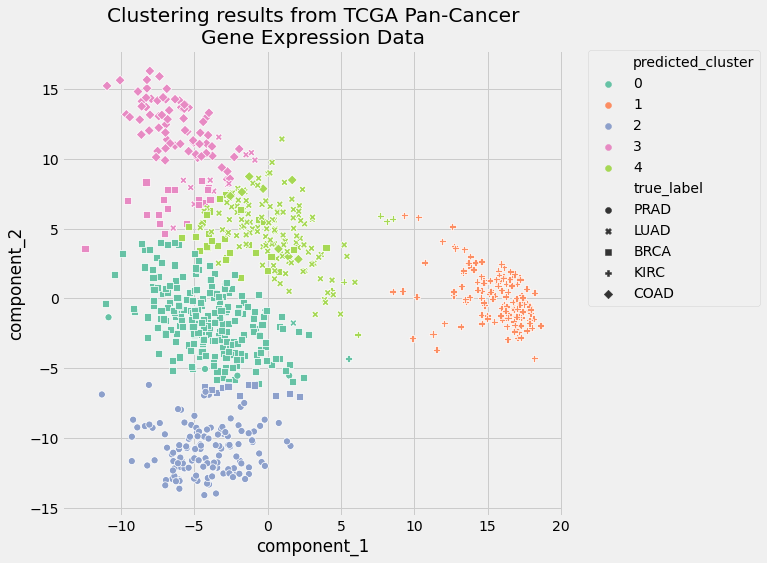
K Means Clustering Images
The 'means' in the K-means refers to averaging of the data; that is, finding the centroid. How the K-means algorithm works. To process the learning data, the K-means algorithm in data mining starts with a first group of randomly selected centroids, which are used as the beginning points for every cluster, and then performs iterative.

Data Mining KMeans Clustering YouTube
Assignment of x to cluster condition — Image by Author. Here's what it means: Ci : This represents the i-th cluster, a set of points grouped based on their similarity.; x: This is a point in the dataset that the K-Means algorithm is trying to assign to one of the k clusters.; d(x,μi ): This calculates the distance between the point x and the centroid μi of cluster Ci .

26. KMeans Clustering Algorithm YouTube
The K means clustering algorithm divides a set of n observations into k clusters. Use K means clustering when you don't have existing group labels and want to assign similar data points to the number of groups you specify (K). In general, clustering is a method of assigning comparable data points to groups using data patterns.

Data Mining KMeans Algorithm (with problems) Clustering
K-means clustering is simple unsupervised learning algorithm developed by J. MacQueen in 1967 and then J.A Hartigan and M.A Wong in 1975. In this approach, the data objects ('n') are classified into 'k' number of clusters in which each observation belongs to the cluster with nearest mean. It defines 'k' sets (the point may be considered as the.
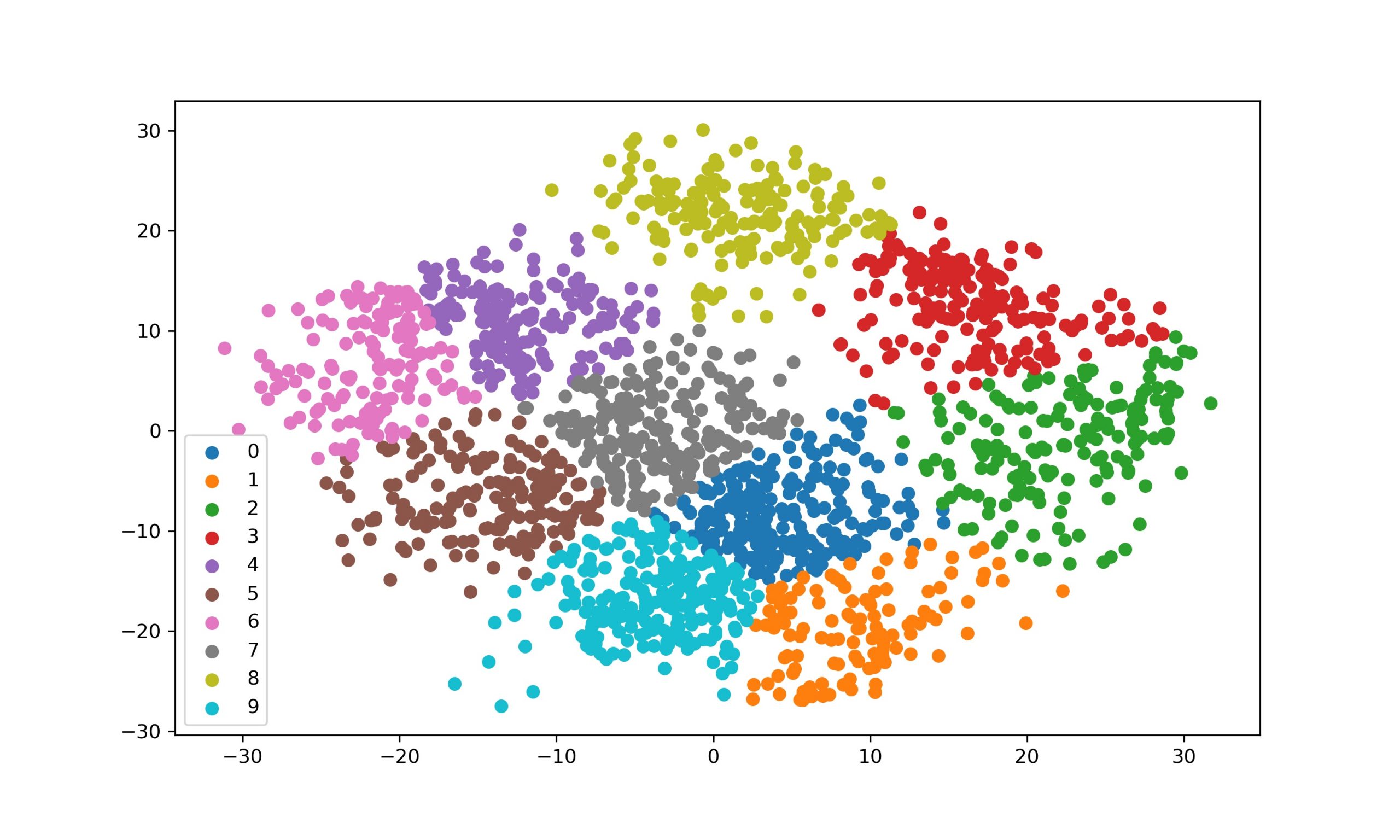
KMeans Clustering From Scratch in Python [Algorithm Explained] AskPython
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster.This results in a partitioning of the data space into Voronoi cells.

k means centroid example k means centroid based technique Data
The K-means method has successfully clustered the data into three distinct clusters. Now let's see what happens with more realistic data. 2. K-means Clustering in Automotive Data. The Python Library Seaborn provides various datasets, including one on automobile fuel efficiency from cars built during the oil crisis era.
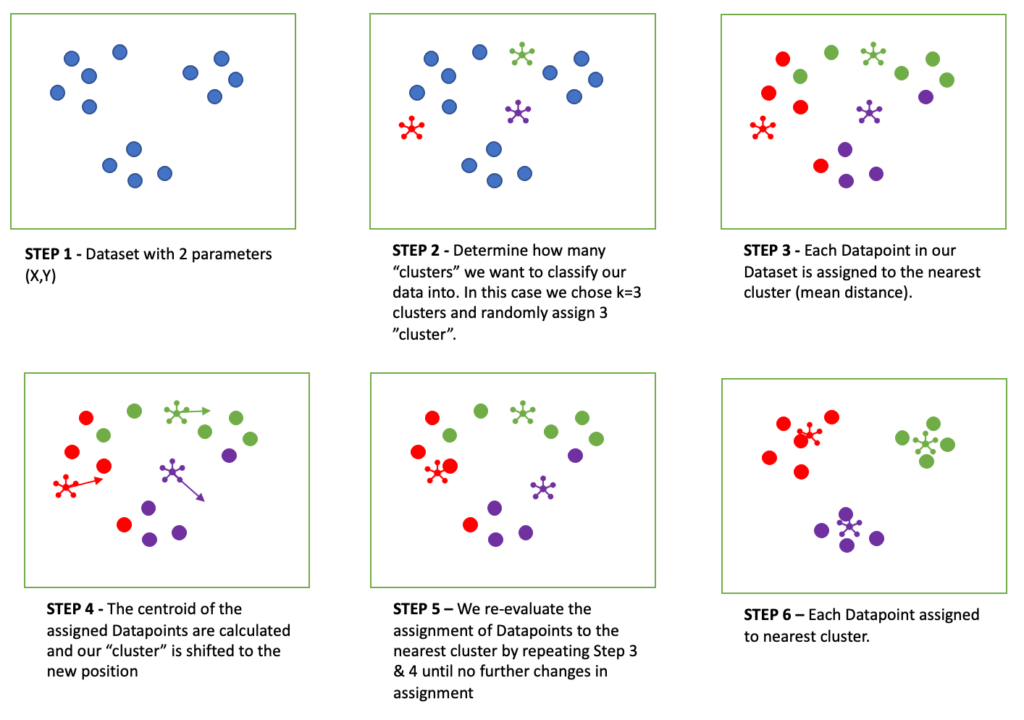
Kmeans Clustering with ScikitLearn FreedomVC
Step 4: Run data mining k-means clustering . Actually most of you may be familiar with iris dataset and know that it has 3 classes in the class label (Sesota, Versicolor, and Virginica) so, we can use k =3 for k-means clustering as discussed above various steps in K-means Clustering. Usually we don't know the correct number of clusters so.

KMeans Solved Problems Data Mining and Warehousing YouTube
K-Means Clustering-. K-Means clustering is an unsupervised iterative clustering technique. It partitions the given data set into k predefined distinct clusters. A cluster is defined as a collection of data points exhibiting certain similarities. It partitions the data set such that-. Each data point belongs to a cluster with the nearest mean.
